
Geleceğin Kütüphanecileri Yapay Zekâ Arşivcileri Olacak
Yazan: Courtney Linder
Çeviren: Ümit Sözbilir
Düzenleyen: Çağla Ayaz & Nergiz Kaşka
Özet: Kongre Kütüphanesindeki bir bilgisayar bilimcisi, tarihî görüntüleri dijital gazete arşivlerinden yalıtmak için makine öğrenimi kullanıyor. Newspaper Navigator adı verilen proje, el yazısı veya metin tabanlı karakterleri aranabilir bir belgeye dönüştürmek için optik karakter tanıma algoritmaları kullanıyor. Makine öğrenimi bu işlem sürecini otomatik hale getiriyor.
Yazılı medya tarihinde fotoğraf baskısını ilk kez, Fransız haftalık gazetesi olan L’illustration, Temmuz 1848’de bir hikâyenin yanına yaptı. Basılan fotoğraf Paris’in Haziran ayaklanması (June Days[1]) sırasında kurulan sokak barikatlarını tasvir etti. Yaklaşık iki yüzyıl sonra fotoğraf muhabirliği, geçmişimizin hikâyelerini anlatan arşiv resimlerini lejyonlarıyla kütüphanelere ulaştırdı. Ancak bunları düzenlemek için yöntemli bir yaklaşım kullanmazsak bu tarihsel görüntüler sonsuz veri yığınlarının arasında kaybolabilir.
Bu yüzden Washington DC’deki Kongre Kütüphanesi bir çalışma yürütmeye başladı. Araştırmacılar gazetelerden tarihî görüntüler çıkarmak için özel algoritmalar kullanıyor. Dijital taramalar zaten fotoğrafları derleyebiliyorsa da bu algoritmalar ayrıca bunları analiz edebilir, kataloglayabilir ve arşivleyebilir. Bu çalışma sonucunda, arşivcilerin basit bir arama ile gözden geçirebileceği, 16 milyon gazete sayfasının değerine eş sayıda görüntü elde edildi.

Kongre Kütüphanesinde ikamet eden, Washington Üniversitesinde bilgisayar bilimi eğitimi alan bir yüksek lisans öğrencisi olan yenilikçi Ben Lee; Gazete Gezgini (Newspaper Navigator) olarak adlandırılan çalışmaya öncülük ediyor. Veri kümesini, 1789 ve 1963 yılları arasındaki dijital gazete sayfalarını derleyen Chronicling America adlı mevcut bir projeden alıyor.
Lee kütüphanenin, bu gazete sayfalarından bazılarını aranabilir bir veri tabanına dönüştürmek için I. Dünya Savaşı ile ilgili içeriğe odaklanarak zaten bir kitle kaynak yolculuğuna başladığını fark etti. Oysa gönüllülerden oluşan bir ekip dijital gazete sayfalarını işaretleyebilir ve yazıya dökebilirdi ki bu işte bilgisayarlar her zaman o kadar da mükemmel değildir. Aslında yaptıkları şey tüm bu yorucu, zahmetli işleri otomatikleştirebilecek bir makine öğrenimi algoritması için mükemmel bir eğitim verisi setiydi.
Lee, Popular Mechanics‘e verdiği demeçte, “Gönüllülerden başlık ve alt yazı gibi şeyler içerecek şekilde sınırlayıcı kutular çizmeleri istendi ve böylece sistem … bu metni belirleyecekti. Yeteneklerimizi artırmak için bazı yeni bilgisayar bilimi araçlarını nasıl kullanabileceğimizi ve koleksiyonları nasıl kullandığımızı görmeye çalışalım istedik.” dedi.
Toplamda, sistemin 16.358.041 gazete sayfasının tümünü gözden geçirmesi yaklaşık 19 günlük bir işlem süresine ihtiyaç duyuyordu. Sistem bunların arasından sadece 383 sayfayı işleyemedi.
Optik Karakter Tanıma Nedir?
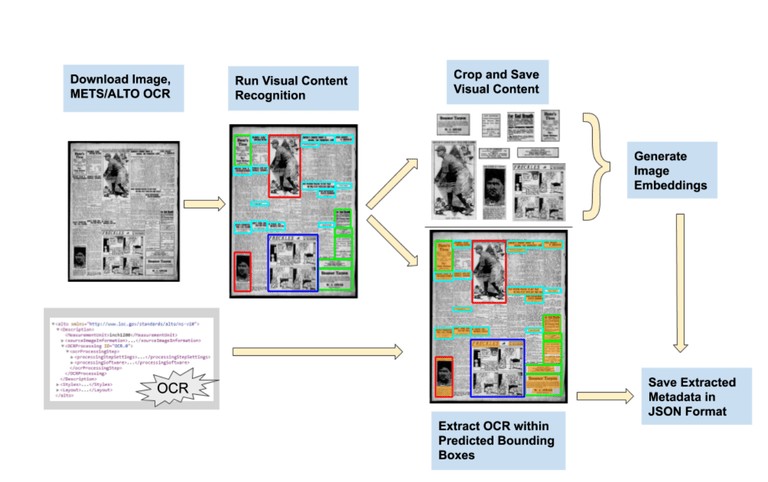
Newspaper Navigator, mühendislerin Google Kitaplar’ı oluşturmak için kullandığı teknolojiyi temel alır. Buna optik karakter tanıma ya da kısaca OKT[2] denir. OKT, taranmış bir dergi sayfasındaki kelimeler gibi yazılı veya el yazısı sembollerin görüntülerini dijital, makine tarafından okunabilir metne çevirebilen bir makine öğrenimi algoritmaları sınıfıdır.
Popular Mechanics‘te, Google Kitaplar’daki neredeyse tüm dergilerimizin bir arşivine sahibiz ve bu dergilerin tarihi Ocak 1905’e dayanıyor. Google bu dijital taramaları uygun hale getirmek için OKT kullandığından tüm arşivimizde “spies (casuslar)” şeklinde bir arama yapıp dolaştığınızda bulacağınız sonuç aşağıdaki gibi olacaktır:

Ancak görüntüler tamamen başka bir şeydir.
Derin öğrenmeyi kullanan Lee; fotoğraflar, illüstrasyonlar, haritalar, çizgi romanlar, başyazı karikatürler, başlıklar ve reklamlar olmak üzere yedi farklı içerik türünü yalıtabilecek bir nesne algılama modeli oluşturdu. Bu nedenle, özellikle siperlerdeki askerlerin fotoğraflarını bulmak istiyorsanız Newspaper Navigator’da “siper” diye arayabilir ve anında sonuç alabilirsiniz.
Daha önce, potansiyel olarak binlerce sayfa değerinde veriyi gözden geçirmek zorundaydınız. Bu atılım, arşivciler için son derece güçlendirici olacak ve Lee, derin öğrenme modelini oluşturmak için kullandığı tüm kodları açık kaynaklı hale getirdi.
Lee, “Umudumuz aslında gazete koleksiyonları olan kişilerin … açık kaynak olarak paylaştığım kodu kullanabilmesi veya kendi sürümlerini farklı ölçeklerde yapabilmeleridir.” diyor. Bir gün yerel kütüphaneniz bu tür teknolojiyi yerel topluluğunuzun tarihini dijitalleştirmeye ve arşivlemeye yardımcı olması için kullanabilir.
Geleceğin Kütüphaneleri?

Bu, sistemin mükemmel olduğu anlamına gelmez. Lee, “Sistemin, özellikle bir illüstrasyonu çizgi film olarak sınıflaması gibi yanlış sınıflamalar yapacağı durumlar vardır.” diyor. Ancak bu yanlış pozitifleri, belirli bir medya parçasının çizgi film veya fotoğraf olma olasılığını vurgulayan güven sonuçlarıyla açıkladı.
Lee ayrıca tüm çabalarına rağmen bu tür sistemlerin her zaman bazı insani ön yargıları kodlayacağını söylüyor. Ancak herhangi bir yanlışı azaltmak için Lee, görüntülerde gerçekte gösterilenlerden ziyade görüntü sınıflarını -reklamlara karşı karikatür- vurgulamaya odaklanmaya çalıştı. Lee, bunun veri kümesi hakkında karar çağrıları yapmaya çalışan sistemin örneklerini azaltması gerektiğine inanıyor. Bunun kütüphane müdürüne bırakılması gerektiğini söylüyor.
Lee, “Bu soruların birçoğunun dikkate alınması gereken çok önemli sorular olduğunu düşünüyorum ve hedeflerimden biri bu projeyi algoritmik ön yargı ile ilgili bazı konuların altını çizmek için bir fırsat olarak kullanmak.” dedi. “Makine öğrenmesinin tüm sorunları çözdüğünü varsaymak kolay -bu bir hayal- ama projede, bu araçları nasıl kullandığımıza dikkat etmemiz gerektiğini vurgulamak için gerçek bir fırsat bulunduğunu düşünüyorum.”
[1] https://en.wikipedia.org/wiki/June_Days_uprising
[2] (İng.) optical character recognition, OCR.





