COVID-19 Salgınını Modellemek Neden Bu Kadar Zor?
Yazan: Matthew Hutson
Çeviren: Mert Günçiner
Düzenleyen: Esranur Maral
Özet: COVID-19 dönemi başladığından beri bu salgının nasıl bir boyuta ulaşacağını tahmin etmek son derece önemli oldu. Zaman içerisinde birçok farklı model geliştirildi fakat hepsi aynı verimi sağlayamadı. Bu modeller, hangi politikaların yürürlüğe konması gerektiğini söyleyebilir ve gelecekteki olası salgınlarla başa çıkma konusunda bize yardım edebilir.
2019’da “eğriyi düzleştirmek” terimi ancak öğrenci notlarını düzenlerken veya kıvrılmış bir halıya basıp onu düzeltirken kullanılabilirdi. Fakat COVID-19 virüsü bulaşmış bireylerin arttığı günümüzde hayati önem taşıyan bu terim, zirve yapmış hasta sayılarını azaltmak adına bir sembol hâline geldi. 2020 yılının başlarında, toplam hasta sayısının hangi sayıya ulaşacağını tahmin eden grafikler birer virüs gibi sosyal ağlarda yayıldı. Böylece hepimiz bizi kaygılandıracak matematiksel olguların sunulduğu eğrileri içeren bu epidemiyolojik modellerin bağımlısı hâline geldik.
Bu tarz modeller senelerce kullanıldı fakat hiç bu derece büyük çaplı bir dikkat toplamamıştı. Bu modeller; kamu politikalarında, finansal planlamalarda, sağlık hizmetlerinin tahsisinde hatta kıyamet günü senaryolarında ve Twitter’da çeşitli vurgunculuklar (spekülasyonlar) yaratmak üzere kullanıldı. 2020’nin ilk çeyreğinde hükûmet liderleri modellerden yola çıkıp bu hesaplamaları kullanarak okulları, iş yerlerini kapattılar ve seyahatleri engellediler. Kontrol edilemeyen bir salgın milyonlarca kişiyi öldürür mü yoksa bir anda yok mu olur? En çok ne tür müdahaleler yardımcı olur? Herhangi bir tahminden ne kadar emin olabiliriz? Bazı insanlar, modeller isteklerine uymadığında hangisi daha çok işine geliyorsa onu kullandı. Bu gibi sorunların ise modelleri tasarlayan ve ne yaptıklarının hâlâ farkında olmayan araştırmacılara bir katkısı olmadı.
Bir salgını modellemenin birden fazla yolu vardır. Bazı yaklaşımlar saf matematiksel soyutlamalardır, sadece doğruları doğru yerleştirmeye çalışır. Bazılarıysa tek bir insandan başlayarak toplumu sıfırdan yorumlamaya çalışır. Bilgisayar bilimcilerinden, epidemiyologlardan ve fizikçilerden oluşan modelciler pandeminin yarattığı karanlıkta doğru yolu bulmaya çalışıyor. Araştırmacılar; gerekli araçları kullanıp onların üzerinde oynama yapıyorlar, yenilerini oluşturuyorlar ve yeni bilgiler edindikçe hangi yöntemlerin çalıştığını öğrenip modellerin ona göre uyum sağlaması için uğraşıyorlar.
Elbette, mevcut salgını bastırmaya çalışıyorlar fakat esas amaçları bu modelleri, mevsimsel grip veya böceklerden kaynaklanabilecek hastalıklar gibi gelecekte karşılaşabileceğimiz herhangi bir hastalıkta bile kullanabilecek noktaya getirmek. Haziran ayında biyolog Lauren Ancel Meyers şöyle dedi: “Bazı yönlerden, salgın başladığı zaman bu salgının gidişatını tahmin edebilme açısından daha emekleme aşamasındaydık.” Teksas Üniversitesindeki COVID-19 Modelleme Birliğinin başkanı Meyers şöyle ekledi: “Sene başında emekleme aşamasındayken son iki üç ay içerisinde yürüme aşamasına geldik denebilir.” Peki ya bu neye yaradı veya neye yaramadı?
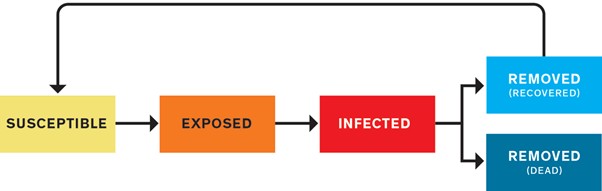
Bir salgını modellemenin “en yaygın yolu” bölmeli (kompartıman) model olarak adlandırılan şeydir. Nüfusu birkaç kategoriye ayırır ve modelin saatinin her geçen saniyesiyle buradaki insanların ne kadarının bir kategoriden diğerine geçiş yaptığını belirleyecek matematiksel kurallar yazarsınız. Öncelikle herkes hastalık kapma riskine sahip durumdadır. Bu insanlar hastalığa duyarlı bireyler olup S (Alan manasındaki “surface” kelimesinden gelir.) bölümünü kaplarlar. Sonrasında bazıları hastalanır (I bölümü, hastalanmış manasındaki “infected” kelimesinden gelir.) sonrasında da ya iyileşerek ya da ölerek patojenin etkisinden kurtulmuş olurlar (R bölümü, kurtulma manasındaki “removed” kelimesinden gelir.). Bu modeller genellikle SIR modelleri olarak bilinirler. SEIR gibi benzer bazı modellerdeyse patojene maruz kalmış ama henüz bulaşıcılık yapmayan bireyler (E bölümü, maruz kalma manasındaki “exposed” kelimesinden gelir.) de bulunur. Eğer iyileştikten sonra kazanılan bağışıklık geçiciyse SIRS ya da SEIRS modellerinde olduğu gibi iyileşen insanları tekrar S kategorisine atmak mümkündür. En basit hâliyle bir model, her kategoride kaç insanın bulunduğunu gösterir ve bu kategoriler arası geçişlerin nasıl olabileceğine dair diferansiyel denklemler içerir. Her denklemin de ayarlanabilir değişkenleri vardır.
SEIRS Modeli
SEIRS modeli insanları kategorilere ayırır: Hastalığa duyarlı bireyler (S), patojene maruz kalmış ama bulaşıcılık yapmayan bireyler (E), hastalanmış ve bulaştırıcı özellikteki bireyler (I), hâlihazırda hastalık kapmış bireylerse (R) iyileştikten sonra kazanacakları bağışıklık durumuna göre sonradan tekrar hastalığa duyarlı bireyler olabilirler (S). Modeli oluşturan araştırmacıların göreviyse bu kategoriler arası geçişlerin hangi matematiksel denklemlerle yönetildiğini tespit etmektir. Bu denklemler biyoloji, davranış bilimi, politika, ekonomi ve hava durumu gibi birçok alandan değişkene bağımlı hâldedir.
Nüfustaki hastalıktan kurtulan insanların (ölmüş ya da iyileşmiş) oluşturduğu grafik genellikle uzatılmış bir S şeklini (sigmoid) alır: ölüm ve iyileşme sayıları önce yavaşça artışa geçer, sonra daha dik şekilde olur, en sonundaysa kademeli olarak düz bir eğri hâline gelir (S harfinin başını ve sonunu çekiştirdiğinizi düşünün.). Hastalığa duyarlı bireyler bu sefer azalacak şekilde aynı eğilimi takip eder: Önce yavaşça, sonra hızlı bir şekilde en sonunda yine yavaşça azalış hareketine devam ederek. İki grafik, azalış ve artış hareketlerine hızlıca (dik bir şekilde) devam ettikleri noktalarda birbirleriyle kesişir. Bu kesişme noktası bir tümsek oluşturur ve buradaki çizgi hastalık kapmış bulaşıcı özellikteki bireyleri (I) temsil eder. İşte düzleştirmek istediğimiz eğri tam da burası. Tümseğin tepe noktasını düşürüp o doğruyu esnetmek istiyoruz ki hastanelere binen yük azalsın.
Doğruların oluşturacağı şekilleri tahmin edebilmemiz için öncelikle denklemleri doğru kurmamız lazım. Fakat bu denklemlerin zamana bağımlı değişkenleri biyoloji, davranış bilimi, politika, ekonomi ve hava durumu gibi birçok alana da bağımlı durumda. Oxford Üniversitesinde epidemiyolog olan Sunetra Gupta’ya göre bölmeli modeller bu işin gözde yöntemlerinden biri fakat “esas soru” bu modelleri nasıl kullanmamız gerektiğidir.
ABD’deki Seattle şehrindeki Washington Üniversitesi Sağlık Ölçütleri ve Değerlendirme Enstitüsünden (the Institute for Health Metrics and Evaluation, IHME) önemli bir araştırma ekibi bir bölmeli model geliştiriyor. Ekip pandeminin ilk başladığı zamanlarda eğri uydurma modeli denilen bambaşka bir yaklaşımla yola çıkmıştı. Bu zamanlarda Amerika Birleşik Devletleri’ndeki vaka sayıları diğer ülkelere kıyasla daha düşük olduğundan bu modele göre zaman içinde ABD’nin grafiği diğer ülkelerin grafikleriyle benzer yapıda olmalıydı. Washington Üniversitesinde epidemiyolog olan Theo Vos’a göre amaç: Çin, İtalya ve İspanya’nın eğrilerine bakarak hastanelerdeki hasta sayısının ulaşacağı tepe noktasını belirlemekti. Mart ayının sonlarına doğru ABD’de daha birkaç bin ölüm sayısı varken IHME, sonraki dört hafta içinde bu sayının 50 bin üzerine çıkacağını isabetli bir şekilde tahmin etti. Nisan ayı olduğundaysa IHME modeli, medyanın ve politikacıların dikkatini çekmeyi başarmıştı. Sonrasındaysa IHME ekibi, Beyaz Saray’ın Koronavirüs Müdahale Koordinatörü Dr. Deborah Birx ve ekibiyle günlük olarak iletişim hâlindeydi.
Fakat IHME modelinin tahmininin aksine ABD’nin eğrisi o kadar kolay düzleşmedi: nisan ortalarında yapılan tahmine göre mayıs ortalarına gelindiğinde ölüm sayısının 60 bini bulması gerekiyordu fakat bu sayı 80 bin oldu. Bu model, haftalar geçtikçe çeşitli epidemiyologlar ve biyoistatistikçiler tarafından sert eleştirilere maruz kaldı çünkü onlara göre belirsizlik içeren etkenlerin kaynağını açıklamakta yetersiz kalıyordu. Aynı zamanda diğer ülkelerde olduğu gibi ABD’deki sosyal mesafe kurallarına layıkıyla uyulacağı gibi hatalı bir tahminle yola çıkarak başka bir hataya düştü. Nisan ayının sonuna gelindiğinde IHME yöneticisi Christopher Murray, modelinin yararlılığını savunurken diğer modellere kıyasla bu model için “Katbekat iyimserdi.” dedi. Mayıs ayının başlarında IHME ekibi, sürekli gelişmeye açık sistemlerine merkezi bir bileşen olarak SEIR modelini ekledi.
Ekip, SEIR denklemlerinin tüm değişkenlerini elle tanımlamakla uğraşmak yerine sisteme verilen girdiyi çözümleyip ileri tahminler yapan Bayes istastik yöntemlerini uygulayan bilgisayarları kullandı. COVID-19 etkinliği devam ettikçe ekibin eline yeni istatistikler geçiyordu: Hastalığın belirtileri ne kadar sürede kendini gösteriyor? Kaç insan hastanelere rapor veriyor? Kaç kişi ölüyor? gibi. Ayrıca internet üzerinden yapılan anketlerle de kaç kişinin maske taktığı, ne kadar insanın sosyal mesafe kurallarına uyduğu ve şehir içi hareketliliğin yoğunluğu hakkında bilgi ediniliyordu.
SEIR modelinin ayarlarını yapabilmek için sistem birçok farklı değişkenin yapılan tahminler üzerindeki başarısına bakıyordu. Tahminlerle en iyi uyuşan değişkenler seçiliyor ve girdilerdeki değişikliklerle birlikte sonraki aylarda kaç kişinin öleceği, ne kadar insanın hastalık kapacağı gibi tahminler yapılıyordu. Bayes yöntemleri birçok belirsizlik içerdiği için model birbirinden biraz farklı binlerce farklı ayarda tekrar çalıştırılıyordu. Bu sayede olası sonuçlar geniş bir ölçekte elde edilebiliyordu.
En önemli ayarlardan bir tanesi de R (“reproduction” kelimesinden geliyor) harfiyle ifade edilen (SEIR’deki R değil) çoğaltma sayısı. Buradaki R, hasta bir insanın kaç kişiye daha hastalık bulaştıracağıdır. Örneğin eğer R 1,0’dan yüksekse ilk evrelerde salgın katlanarak büyür, 1,0’ın altındaysa yok olur. “Bir SEIR modelini nasıl evcilleştireceğimizi öğrendik.” diyen Vos şöyle ekliyor: “En ufak bir değişikliğe bile çok fazla tepki veriyorlar. Eğilim katlanarak artmak veya azalmak oluyor.” Tamamen soyut bir model, gerçek dünyadaki sosyal ve çevresel etkenlerle sınırlandırılmaz ve R değişkenindeki en ufak bir değişiklik bile çılgınca sonuçlar doğurur. Eğer istatistiklerinizdeki değişkenlerin ayarlarını çok güçlü verilerle desteklemezseniz Vos’a göre: “Elde edeceğiniz sonuçlar deli saçması olur.”
Veriye Dayalı Model
Veriye dayalı modeller insanları kategorilere ayırmaz, sadece sayılarla çalışırlar. Bazı veriye dayalı modeller yapay sinir ağlarını[1] kullanır. Basit bir örnek verirsek eğitilmiş[2] bir yapay sinir ağı, belirli çıktıları tahmin etmek için geniş bir girdi kümesi içerisindeki ilişkilerden anlam çıkarmaya çalışır. Modellemeyi yapan kişi modelin içerisindeki binlerce değişkeni tek tek bilemediği ve anlayamadığı için buradaki sinir ağı bir “kara kutudur.”
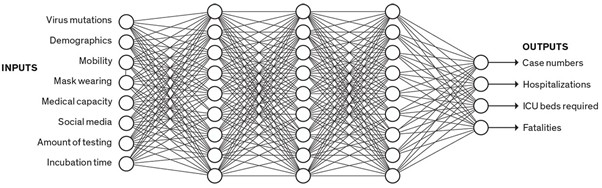
Bölmeli modellerde makine öğrenmesi kullanan başkaları da oldu. YYG adlı bir model, yaptığı başarılı tahminlerle ABD Hastalık Önleme ve Kontrol Merkezlerine (CDC) bilgi sağladı. YYG modeli, yalnızca bilgisayar bilimleri alanında Massachussets Teknoloji Enstitüsünde yüksek lisansı olan Youyang Gu ve bağımsız çalışan veri bilimcilerle işletildi. Bu model gayet basit bir şekilde çalışıyor: veri olarak yalnızca günlük ölüm sayılarını kullanarak. Bu istatistiklerle birlikte ızgara araması[3] (grid search) kullanılarak çoğaltma sayısı, hastalık kapanların ölüm oranı, karantina sıklığı gibi değişkenler ayarlanır. Her bir değişken için birkaç seçenek sunulur ve verilerle en iyi uyuşan küme bulunana kadar her bir eşleşme test edilir. Bir bakışla üstünüze en iyi uyacak giysileri seçmek gibidir: Hadi şimdi kırmızı tişörtümüzle birlikte yeşil pantolonumuzu ve sarı çoraplarımızı deneyelim.
“Mart ayının sonlarındaki ve nisan ayının başlarındaki modellerin kalitesi beni hayal kırıklığına uğratmıştı.” diyen Gu şöyle devam ediyor: “O zamanlar medyada sıklıkla dile getirilen IHME eğri uydurma modeline kalırsa ‘Haziran ayına kadar ölüm sayıları sıfıra ulaşacaktı.’ Ortadaki verilere baktığımda bunun olamayacağı ortadaydı. İşte o zaman kendi modelimi oluşturmaya koyuldum.” 9 Mayıs tarihine kadar ABD’deki ölüm sayıları Gu’nun tahminleriyle tamamıyla uyuşarak 80 bin civarına ulaştı. Bununla birlikte bir hekim ve halk sağlığı lideri olan Eric Topol, YYG modelini överek onun “en isabetli COVID-19 modeli” olduğunu belirtti.
“Gösterdiğimiz üzere bizimki gibi basit bir model bile iyi iş çıkarabiliyor.” diyen Gu, basitliğin bir diğer faydasının da çeviklik olduğunu belirterek şöyle ekliyor: “Basit olduğu için üzerinde yapacağım değişikliklerle hızlı bir şekilde ilgilenebiliyorum.” 50 eyalet ve 70 ülke adına tahmin yapabilmek için bilgisayarında 30 dakikanın altında bir süre geçirmesi yetiyor. Ek olarak, az değişkene sahip basit modeller yeni durumlarla karşılaştığında onları rahatlıkla genelleyebiliyor ve sonuçlar daha kolay anlaşılabiliyor.
SEIR modellerine bir diğer seçenek ise veriye dayalı modeller. Georgia Teknoloji Enstitüsünde bilgisayar bilimci olan B. Aditya Prakash, bu modellerin insanları kategorilere ayırmadan veriler üzerinde çalışabildiğini söylüyor. O ve ekibi, on binlerce değişkene sahip geniş yapay sinir ağları olan birtakım derin öğrenme modelleri kullanıyor. Bu ağlar, girdi verileriyle (hareketlilik, yapılan testler ve sosyal medya verileri gibi) pandemi sonuçları (hastaneye yatan hasta sayısı ve ölüm sayısı gibi) arasından karmaşık ilişkiler çıkarır.
Prakash’ın belirttiği üzere veriye dayalı modeller, “karışık, herhangi bir epidemiyolojik karşılığı olmayan sinyaller” üzerinde çıkarım yaparken iyi olabilir. Örneğin, hastanelere gitmek gibi “gürültülü” bir sinyal yalnızca toplam hastalık sayısına bağlı değildir. Ancak bir insanın hastaneye gidebilmesini açıklayabilecek sosyolojik ve ekonomik etkenler göz önünde bulundurulduğunda hastalanan bireyin evde mi kalacağına yoksa hastaneye mi gideceğine karar verilebilir. Fakat Prakesh’e göre bölmeli modeller derin öğrenmeyle çalışan modellere kıyasla varsayımlar yapmakta daha etkili: Çeşitli politikaları yürürlüğe koyup R (çoğaltma) sayısını %20 kadar azaltabilirsek eğrimiz ne kadar değişir? Bu varsayımlarda bu kadar etkili olabilmesinin sebebi, kontrol ayarlarının daha göz önünde olması. Ayrıca SEIR modellerinin epidemiyolojik teoriye bağımlı olması sebebiyle onunla uzun vadeli tahminler yapabilmek daha etkili. Derin öğrenme daha çok verilere bağımlı, dolayısıyla kısa vadede çok daha etkili. Fakat binlerce anlaşılmaz değişkenin bu öğrenme sürecini yürütmesinden dolayı bir kara kutu olan derin öğrenme, daha uzun vadede yapılacak tahminler söz konusu olduğunda çuvallayabilir.
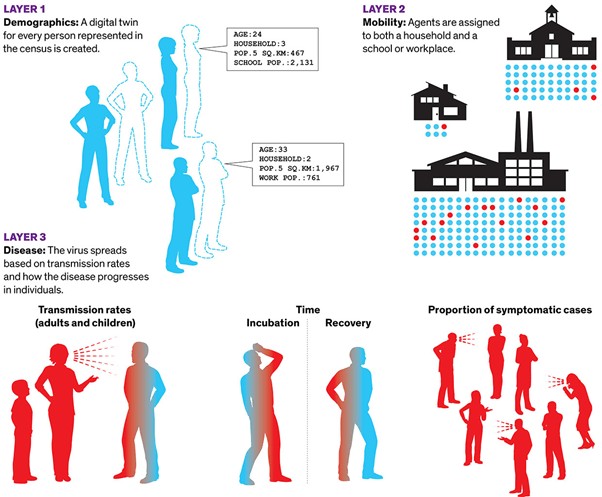
Eğer tüm modelleri bir tayfa yatırırsak “veriye dayalı modeller” bu tayfın sayılarla çalışan daha soyut kısmını işgal ediyor. Buna karşılık, etmen tabanlı modeller bu tayfın çok daha gerçekçi tarafında yer alıyor. Bu modeller daha çok The Sims oyunu gibi. Nüfustaki her insan kendi özel koduyla temsil ediliyor, bu insanlara da etmenler deniliyor. Bu “etmen” insanlar birbirleriyle etkileşime girip dünya üzerinde dolaşıyorlar. En başarılı etmen tabanlı modellerden biri Sidney Üniversitesinde geliştirildi. Bu model demografik bir katmanla başlayacak şekilde üç katman içeriyor. Sidney Üniversitesinde bilgisayar bilimci olan Mikhail Prokopenko şöyle açıklıyor: “Esasında yarattığımız şey nüfus sayımında temsil edilen her bir insanın dijital ortamdaki ikizleri.” O ve iş arkadaşları, 24 milyon nüfuslu Avusturalya ülkesini sanal ortamda oluşturdular. Yaş, hane büyüklüğü, mahalle büyüklüğü ve okul büyüklüğü gibi her bir gerçek veri temsil edildi. İkinci katman ise hareketlilikti. Burada her bir “etmen” evlerine, okullarına veya iş yerlerine atandı. Demografik ve hareketlilik katmanlarının üzerine bir de hastalık eklendi. Böylece ev, okul ve iş yerleri içerisindeki insanların diğer bireylere hastalık bulaştırma hızları ölçüldü. 2018’de buna benzer bir model daha eski bir nüfus sayımı kullanılarak grip hastalığı için yapılmıştı. COVID-19 salgını başladığında bu modeli gelecekteki grip hastalığı araştırmaları için güncelliyorlardı. Bu yüzden hastalık bulaştırma katmanında görülebilecek ayırt edici özellikleri tespit etmek için çalışmalarına devam ettiler.
Etmen Tabanlı Model
Etmen tabanlı modeller, belirli bir nüfustaki insanların gerçek dünyadaki etkinliklerini sanal bir dünya yaratarak inceler. Sidney Üniversitesinden araştırmacılar üç katmanlı bir COVID-19 modeli oluşturdular: nüfus sayımında temsil edilen her bireyin sanal ortamdaki ikizi; bu bireylerin evlerinde, okullarında ve iş yerlerindeki hareketliliklerini temsil eden bir hareketlilik katmanı ve hastalığın ayırt edici özelliklerinin temsil edildiği diğer katman.
Harekete geçtiği sırada model, günde iki kere uyarılır: İnsanlar gün içerisinde okulda veya iş yerinde, gece vaktiyse evde birbirleriyle temas kurarlar. Bir zarı bir bakıma tekrar tekrar atmak gibidir. Model birkaç saat içerisinde 180 günü kapsar. Ekip, bir dizi sonuç elde edebilmek için genellikle modelin yüzlerce kopyasını bir bilgi işlem kümesi içerisinde beraber çalıştırır.
Sidney ekibinin kayda değer bir bulgusuysa sosyal mesafe kurallarına yönelikti: Toplumun %70’i bunlara uyarsa beklenen etki çok zayıf kalıyor fakat %80 ve üzeri bir uyumluluk olursa COVID-19 yalnızca birkaç ay içerisinde yok olabilir. %90’lık bir uyumluluksa aynı etkinin çok daha hızlı şekilde sonuçlanabildiğini gösterdi. Hem federal hükûmete hem de Avusturalya üniversitelerine bu modelin raporları gönderildi ve hatta Dünya Sağlık Örgütü de iki raporla bilgilendirildi. “Çok memnun kaldık.” diyen Prokopenko şöyle devam ediyor: “Uzun zamandır avukatlığını yaptığımız etmen tabanlı modeller tam da gerektiği zamanda meyvesini verdi.”
Prokopenko’ya göre SEIR modelleri Avusturalya’da “pürüzlü” bir iş çıkardı ve bu modellerin tahminleri büyük ölçüde yanlış çıktı. Dahası, varsayımları keşfetme konusunda işe yarıyorlar fakat bunlarla nasıl müdahale edilebileceğini söyleyemezler. Örneğin, SEIR modelinin size R sayısını %20 indirirseniz pandeminin yayılma hızının yarı yarıya düşeceğini söylediğini düşünün. Peki gerçek dünyada bu R sayısını hangi yollarla %20 oranında azaltabiliriz? Etmen dayalı modellerle birlikte insanların haftada bir gün evde kapalı kaldığı bir durumun çözümlemesi yapılıp bu tür bir uygulamanın etkileri gözlemlenebilir.
Şu zamana kadar etmen tabanlı modeller bu kadar geniş ölçekli kullanılmamıştı. Bunun sebebi muhtemelen günümüze kadar bu denli büyük hesaplama gücüne sahip olmamamızdı. Aynı zamanda ayarlarını yapmak da o kadar kolay olmuyor. Araştırmacılar, hasta yetişkinlerin belirti gösterme oranını çocuklarınkine kıyasla daha yüksek yaptığında Sidney modelinin tahminleri gerçeğe daha çok yaklaşmıştı. Bu durum COVID-19’u bildiğimiz gripten ayıran özelliklerden bir tanesi. Prokopenko şöyle açıklıyor: “Şimdi etmen tabanlı modelleri geniş ölçekte test edebilmemizi sağlayacak teknoloji ve uzmanlığa sahip olduğumuza göre bu modeller önümüzdeki olası pandemilerde çok daha etkili olacak.”
Bu pandeminin modellemesini yapan araştırmacılar, yapım aşamasında çok şey öğrendiklerini söyledi. Pandemi sırasında, gelecekte bize katkı sağlayacak dersler çıkarıldı.
Çıkarılan ilk dersler tamamıyla verilerle ilgili. Dedikleri üzere: Çer geliyor, çöp gidiyor. CDC tahmin merkezinin çalışmalarına yardımcı olan Iowa Eyalet Üniversitesinden istatistik profesörü Jarad Niemi’ye göre neleri tahmin ettiğimiz tam olarak net değil. Hastalık kapma, ölüm ve hastaneye yatış sayılarının her biri yalnızca girdi olarak değil aynı zamanda çıktı olarak sağlayabilecekleri katkıları etkileyen kendi sorunlarına sahip. Hastalığın ne kadar yayıldığının gerçek verisini herkes test edilmeden bilemeyiz. Ölümleri saymak daha kolay fakat onların oranları da hastalık kapıldıktan haftalar sonra ele geçiyor. Planlama yapma konusunda hastaneye yatış sayıları önemli fakat her hastane bu verileri paylaşmıyor. Eğer gerçek sayıları hiçbir zaman elde edemiyorsak karşılaştırmalı tahminler yapmak ne kadar yararlı olacak? Niemi’ye göre ihtiyacımız olan şey sistemli bir şekilde nüfustan rastgele seçilmiş insanlara yapılacak testler. Bu sayede hâlihazırda hastalık kapmış veya iyileşmeyi ifade eden antikora sahip insanlar hakkında daha sağlam verilere sahip olabiliriz. Georgia Teknoloji Enstitüsünden Prakash’a göre hükûmetlerin görevi merkezi konumlarda hızlı bir şekilde bilgi toplayıp o bilgileri paylaşmak. Ayrıca Prakesh için politika kararlarıyla bağlantılı merkezi veri depolarını oluşturmak önemli. Modelciler, bu sayede hangi bölgelerin sosyal mesafe kurallarını daha iyi uyguladığını öğrenebilir.
Araştırmacılar aynı zamanda modellerin çeşitliliğinin önemliliğinden bahsetti. Basit düzeyde, bir tahmin topluluğunun ortalamasını almak güvenirliliği artırır. Daha da önemlisi, her bir modelin kendi ayrı kullanım alanları ve tuzakları vardır. Bir SEIR modeli uzun vadeli tahminler yapmak için görece basit araçlara sahiptir fakat şeytan bu modelin değişkenlerinde gizleniyor: Bu değişkenleri hem günümüzle hem de gelecekle uyuşabilecek şekilde nasıl ayarlayacaksın? Onları yanlış ayarladığınız zaman karşınıza fantastik bir dünya çıkabilir. Veriye dayalı modeller söz konusu olduğunda kısa vadeli tahminler yapmak daha etkili olur ve makine öğrenmesi karmaşık etkenlerle başa çıkabilir. Ancak koşullar değiştiği vakit yapay sinir ağları hâlâ güvenilir olmaya devam edebilecek mi? Etmen tabanlı modeller, hangi politikaların uygulanması gerektiğini ve sanal ortamda yapılacak müdahaleleri test edebilir. Fakat bu modelleri yapmak ve en uygun ayarlara getirmek bir o kadar da zahmetli.
Son olarak, araştırmacılar çevikliğin gerekliliğini vurguluyor. Iowa Eyalet Üniversitesinden Niemi’ye göre yazılım paketleri sayesinde modelleri hızlı bir şekilde inşa etmek kolaylaştı. GitHub gibi internet siteleri sayesinde insanlar kendi modellerini paylaşıp diğerleriyle kıyaslayabiliyor. Teksas Üniversitesinden Meyers’in belirttiği gibi COVID-19 dönemi modelcilere yeni aletlerini test etmek için uygun bir ortam sağlıyor. Meyers şöyle bağlıyor: “Yeni istatistiksel yöntemler, yeni veri türleri ve yeni model yapıları var.”
“Bu virüsü yenmek istiyorsak eğer” diyen Prokopenko şöyle bitiriyor: “yeni koşullara en az onun kadar uyum sağlayabilmeyi öğrenmeliyiz.”
[1] İnsan beyni temel alınarak geliştirilen bilgi işlem teknolojisi. (Kaynak: Vikipedi)
[2] Sistemin çalışması ve öğrenmesi için verilen veri türü. Bu verileri kullanarak makine öğrenmesiyle eğitilen sistem ileride incelenecek verilere (test verileri) karşı hazırlıklı hâle gelir.
[3] Sisteme girilecek eğitim verilerinin en uygun şekilde sonuç vermesi adına elle yapılan yorucu bir arama yöntemi.
(Kaynak: https://en.wikipedia.org/wiki/Hyperparameter_optimization) (İleri okuma için: https://medium.com/deep-learning-turkiye/derin-ogrenme-uygulamalarinda-model-dogrulama-ve-hiper-parametre-secim-yontemleri-823812d95f3)